Dalla mente al modello: Stable Diffusion come ponte tra l’idea e la sua rappresentazione visiva

Introduzione
L’esperienza nell’integrazione dell’Intelligenza Artificiale (IA) nel processo di progettazione di ATI Project continua a evolversi con l’utilizzo di diverse piattaforme che permettono maggiore velocità e chiarezza nelle prime fasi del processo creativo. Nel precedente articolo, Al nostro tavolo siede un nuovo alleato: l’IA, abbiamo esplorato il ruolo di Midjourney nella visualizzazione e valutazione dei concept progettuali, evidenziando come questa tecnologia consenta una rapida esplorazione di diverse idee e soluzioni. In questo articolo, ci concentreremo sulla seconda fase dello sviluppo del concept individuato, analizzando l’impiego di ulteriori strumenti di generazione delle immagini e il loro impatto nel perfezionamento del processo progettuale.
Stable Diffusion e i modelli di diffusione latente
Midjourney è solo uno dei vari strumenti disponibili nel mercato delle IA generative. Tra i più importanti e utili troviamo Stable Diffusion: una piattaforma di Intelligenza Artificiale che utilizza una tecnica chiamata “diffusione generativa” per generare immagini di alta qualità a partire da descrizioni testuali (text-to-image) o per migliorare e modificare immagini esistenti (image-to-image).
Ma come funziona esattamente?
I modelli di diffusione sono una tipologia di modelli generativi che apprendono come manipolare le immagini attraverso due fasi complementari: l’aggiunta di rumore e la sua successiva rimozione.
Nel primo stadio, noto come noising, il modello impara ad aggiungere progressivamente rumore a un’immagine. Questo processo, che distorce gradualmente i dettagli visivi, è essenziale per addestrare il modello a comprendere come si sviluppano e si diffondono i pattern di rumore nelle immagini. Una volta che il modello ha acquisito questa abilità, viene insegnato a fare l’opposto: attraverso il processo di denoising, il modello rimuove il rumore passo dopo passo, restituendo un’immagine sempre più chiara e definita. Ad ogni passaggio, l’immagine si avvicina progressivamente alla sua forma originale, con maggiore dettaglio e precisione.
La qualità finale dell’immagine dipenderà quindi dalla capacità del modello di recuperare le informazioni visive nascoste dal rumore, affinando ulteriormente il livello di dettaglio e la precisione in ogni passaggio.
Per orientare questo processo, il modello di diffusione utilizza un sistema sviluppato da OpenaAI e chiamato CLIP (Contrastive Language-Image Pretraining), che converte la descrizione testuale fornita dall’utente in una rappresentazione numerica, guidando così il processo di denoising e permettendo all’intelligenza artificiale di affinare l’immagine. Questo approccio garantisce che il risultato finale sia coerente con la descrizione fornita.

Tuttavia, lavorare direttamente sulle immagini in uno spazio visibile fatto di pixel, richiederebbe un enorme dispendio di risorse computazionali. Per questo motivo, Stable Diffusion utilizza uno spazio latente, che è una rappresentazione compressa e astratta dell’immagine. In questo spazio, l’elaborazione avviene in modo più efficiente, poiché i dati sono ridotti senza perdere le informazioni essenziali per generare un’immagine di alta qualità.
Il processo è reso possibile grazie a un sistema chiamato encoder-decoder. L’econder prende l’immagine dallo spazio originale e la trasforma in una rappresentazione nello spazio latente. Nel caso di Stable Diffusion, l’econder è un VAE (Variational Autoencoder), che crea rappresentazioni continue e strutturate in questo spazio. Una volta che l’immagine è stata compressa nello spazio latente, entra in gioco il decoder, che compie l’operazione inversa, riportando la rappresentazione latente allo spazio originale e generando un’immagine dettagliata e ad alta risoluzione.
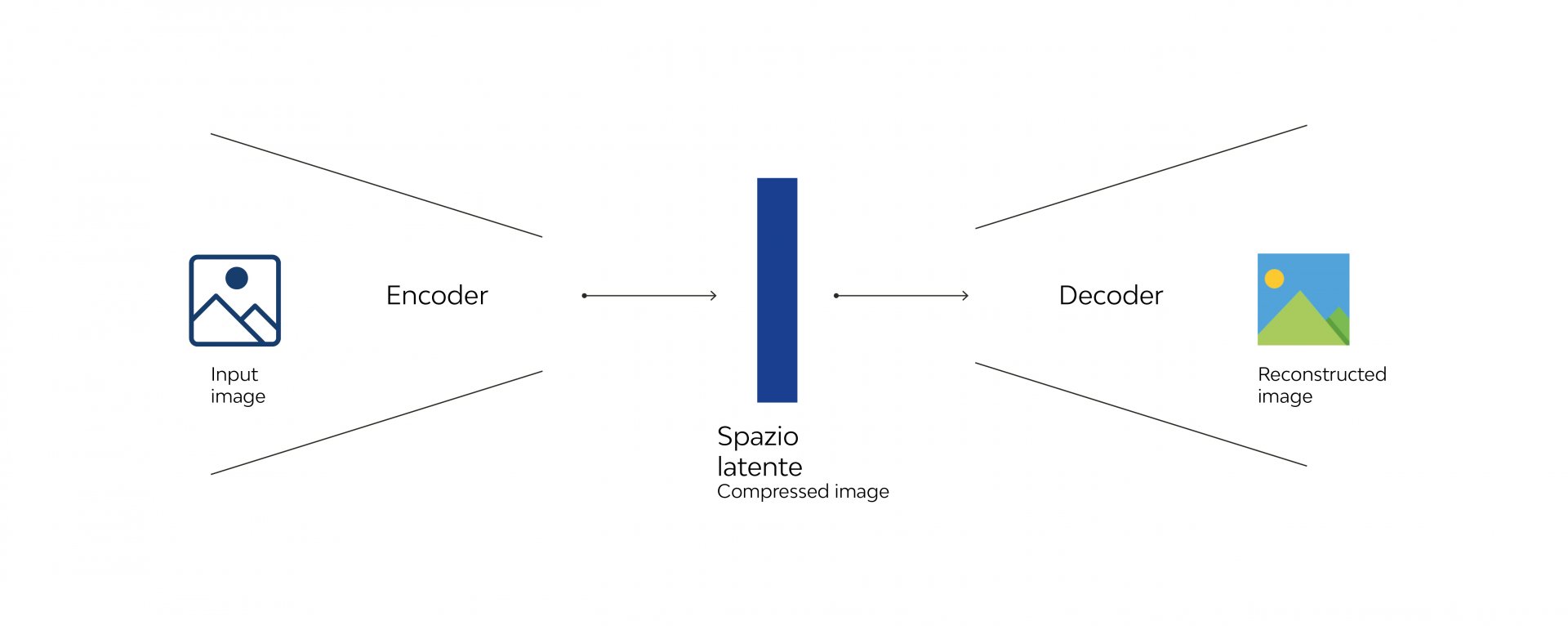
Come già accennato, le due principali funzionalità di Stable Diffusion sono text-to-image e image-to-image. Nel primo caso, il sistema genera un’immagine partendo da un prompt testuale, mentre nel secondo, si utilizza sia il prompt che un’immagine base di partenza, per ottenere un risultato visivamente simile.
Stable Diffusion offre, inoltre, la possibilità di effettuare modifiche alle immagini tramite inpainting nella sezione image-to-image. Questa funzionalità consente di creare maschere sulle immagini, a cui si associa un prompt per aggiungere dettagli o modificare porzioni dell’immagine. Infine, è possibile creare video tramite text-to-video o video-to-video, ampliando ulteriormente le possibilità creative.
Influenzare l'output: L'importanza dei parametri in ControlNet
Ad ampliare le possibilità di Stable Diffusion c’è ControlNet, una tecnologia avanzata progettata per fornire un controllo preciso e condizionato durante la generazione delle immagini.
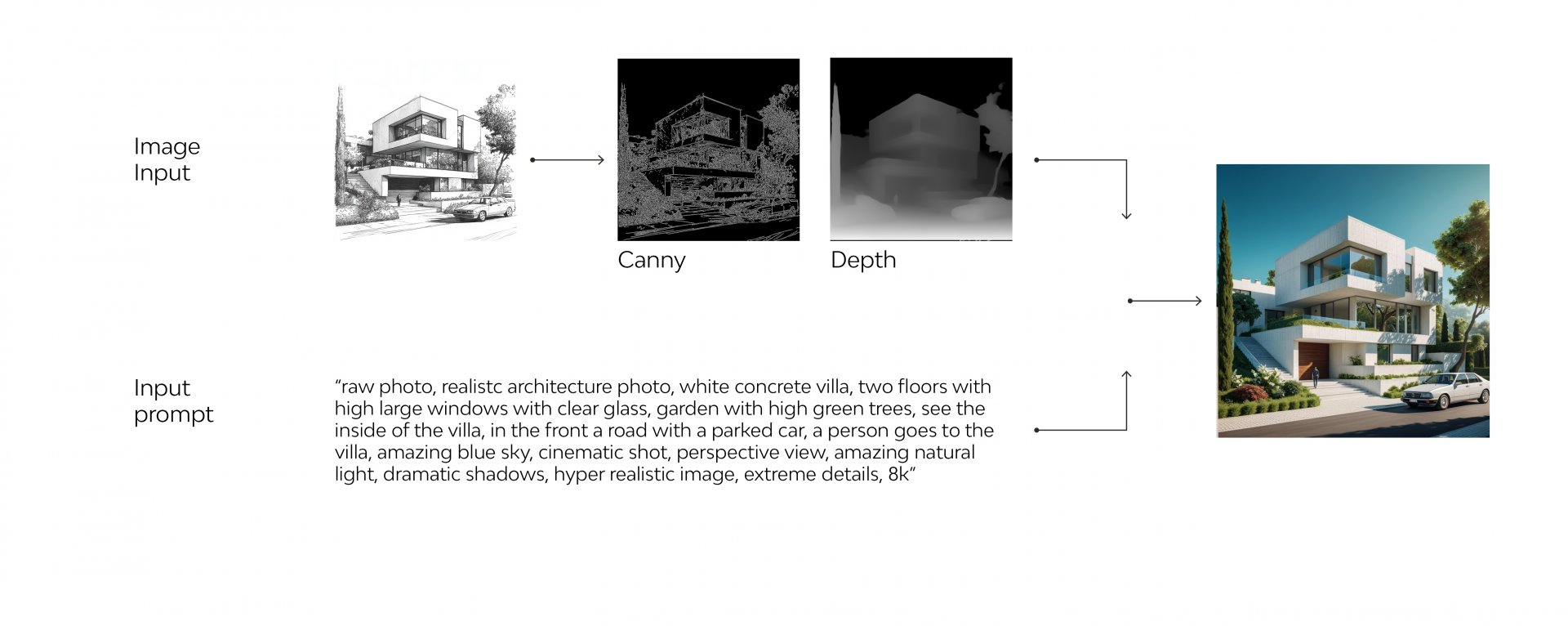
ControlNet si basa sull’idea di guidare il processo di diffusione latente utilizzando input strutturati come immagini di riferimento, mappe di profondità, contorni, pose o altre informazioni aggiuntive. Questo approccio consente, infatti, di mantenere la flessibilità creativa del modello, pur rispettando specifiche condizioni.
Il funzionamento di ControlNet si articola in un processo che integra una rete parallela (control network) al backbone del modello di Stable Diffusion. Il backbone è il modello neurale pre-addestrato che si occupa della generazione delle immagini, il quale viene “congelato” così da non essere modificato mentre la Control Net influenza il percorso di generazione per far rispettare i vincoli fortini. La rete ControlNet, addestrata separatamente, riceve come input dati strutturati, come mappe di contorni (ad esempio Canny o Lineart), mappe di profondità (Depth) o altre informazioni specifiche. Questi dati vengono elaborati all’interno dello spazio latente, ed il percorso di generazione influenzato dalla control net, consente di mantenere i dati dell’input durante il processo di denoising.
Il risultato è un’immagine finale che non solo viene perfezionata, ma resta fedele ai vincoli imposti dall’input iniziale, garantendo che la generazione rispetti le specifiche richieste. ControlNet offre così maggiore precisione nel controllo dei dettagli, rappresentando uno strumento potente per artisti e designer che vogliono integrare l’intelligenza artificiale nei propri flussi di lavoro creativi.
ControlNet si presenta, quindi, come una vera e propria estensione rivoluzionaria, che amplia la versatilità di Stable Diffusion, offrendo nuove opportunità per la personalizzazione e la fine-tuning delle immagini generate.
Caso studio
Tornando al caso studio trattato nell’articolo precedente, passiamo ora al secondo step del flusso di lavoro, che richiede un controllo maggiore sull’immagine per mantenere fedeltà alla volumetria e alle caratteristiche del progetto.
Ci focalizzeremo su una delle opzioni proposte dalla matrice generata con Midjourney, non selezionata come soluzione progettuale finale, ma che offre l’opportunità di approfondire diversi step di interazione con l’IA. Il concept in analisi presenta un involucro caratterizzato da elementi verticali di altezza variabile, il cui sviluppo richiede strumenti avanzati per una generazione più accurata delle immagini.
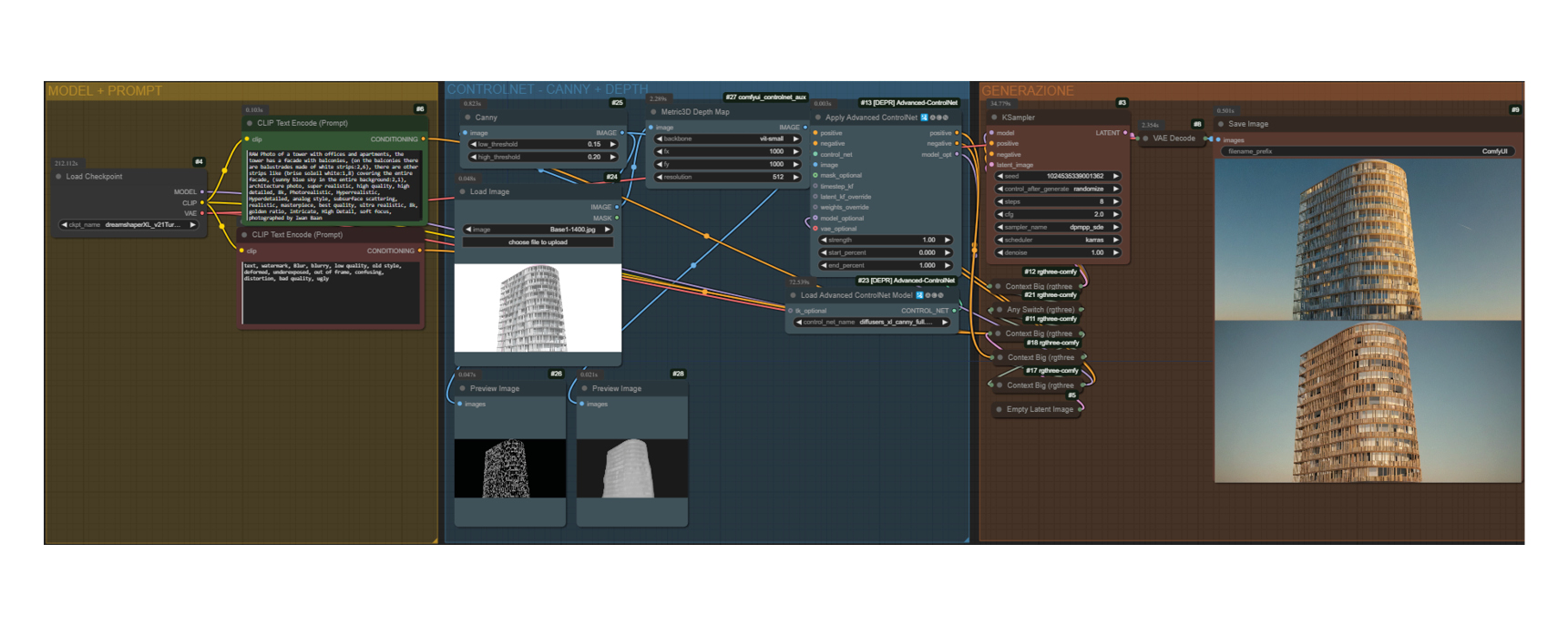
A tal fine, abbiamo scelto di utilizzare Comfy UI, un’interfaccia utente avanzata per la gestione di modelli di Intelligenza Artificiale basati su Stable Diffusion. Comfy UI offre un ambiente modulare e altamente personalizzabile, con una programmazione visiva che permette di costruire flussi di lavoro complessi combinando nodi visivi. Grazie alla sua flessibilità, è possibile adattare l’interfaccia a diverse esigenze. Nel nostro caso sono stati utilizzati due flussi principali: image/sketch to render e generazione in tempo reale da modello 3D Revit e Speckle.
Segue la descrizione degli step principali del processo:
Step 1: Image/sketch to Render
Come primo step è stata utilizzata un’immagine base della Torre sotto forma di sketch, alla quale sono state aggiunte diverse soluzioni di listelli verticali sulla facciata. In questa fase, è possibile visualizzare l’intero edificio con la soluzione integrata.
La generazione di un’immagine fedele allo sketch, così come per altri tipi di input visivi, è stata realizzata tramite l’estensione ControlNet. Quest’ultima è particolarmente utile in contesti in cui si parte da un semplice schema o planimetria per ottenere rendering complessi e personalizzati, garantendo al contempo la coerenza con i dettagli desiderati.
Per aumentare il controllo sull’aspetto dell’immagine, è stato utilizzato anche IPadapter, che aiuta a guidare lo stile dell’immagine. IPadapter si basa su una rete adattativa che fornisce input aggiuntivi al modello, influenzando il risultato finale con dati specifici, come immagini di riferimento, stili o texture. In questo caso, l’immagine di riferimento utilizzata è quella generata da Midjourney. Di seguito, si passa alla fase successiva: la creazione di un modello 3D dettagliato.
Step 2: Generazione Real Time da modello 3D Revit e Speckle
Con la creazione di un modello 3D, prima di passare alla fase finale, viene utilizzato Grasshopper per facilitare la disposizione degli elementi verticali sulla facciata. Questo strumento permette di gestire con precisione dimensioni, altezze, distanze e altri parametri, ottimizzando così il processo e aiutando a ottenere la soluzione più adeguata in tempi rapidi.
Il modello viene successivamente importato in Speckle, un programma che facilita l’importazione e l’esportazione di dati 3D, consentendo di applicare texture con maggiore precisione e semplificare operazioni complesse come la proiezione UV e la gestione dei materiali fisicamente corretti.
Grazie ai “nodi” specifici all’interno di Comfy UI, è possibile collegare la visualizzazione del modello in Speckle e utilizzare questo collegamento per generare immagini in tempo reale. Queste immagini si adattano agli spostamenti dell’utente nel 3D, offrendo così la possibilità di visualizzare render in tempo reale delle diverse viste e soluzioni dell’edificio.
Conclusione
La generazione di immagini come di video attraverso l’IA sta vivendo un’espansione continua, con aggiornamenti e nuovi modelli che ogni mese aprono nuove possibilità, migliorando il controllo e la velocità degli output finali in modi sempre più sorprendenti. Questa metodologia non solo accelera i processi decisionali, ma eleva anche la qualità del risultato finale, consentendo ai team di progettazione di visualizzare in tempo reale l’impatto delle proprie scelte.
L’integrazione dei flussi basati sull’IA si conferma dunque un elemento cruciale per l’innovazione nel settore architettonico, combinando creatività, tecnologia e precisione in ogni fase del progetto.
Esplora il modello 3D
Video
#StableDiffusion #MidJourney#ControlNet #AIInDesign #InnovativeDesign #DigitalDesign #CreativeProcess #ImageGeneration #LatentDiffusion #ArchitecturalRendering #ConceptDevelopment #AdvancedDesign #AIForArchitecture #AIForCreativeWorkflows #AI #ImageToImage
